![]()
Everyone in the SEO community is talking about how John Mueller’s website is no longer listed in the Google Search results. It seems like it was deindexed and removed from Google completely. The question is why? John Mueller is one of the most recognized Google Search spokespeople on the internet, so for his site, johnmu.com, with a ton of geeky topics on it, to be not showing up in the Google Search results – SEOs wonder…
If you do a site command for [site:johnmu.com] – no results come up: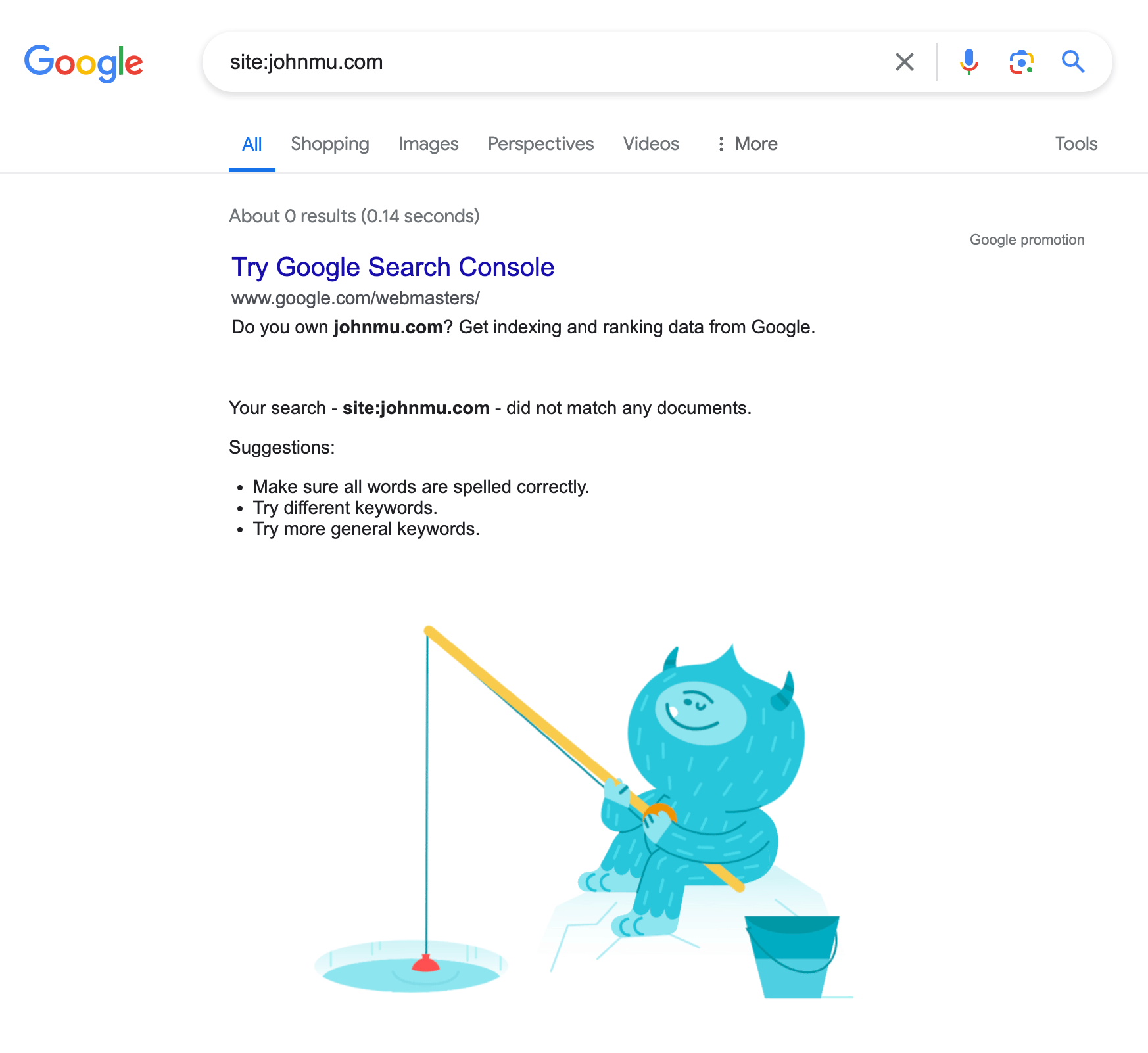
Of course, first thing every SEO does it inspect the johnmu.com/robots.txt – so have fun going through that. Then you look for other meta tags that might prevent it from being indexed.
We do not have access to John’s Google Search Console to see if there was a manual action, like so many other sites received last week, but I doubt his site was hit by one…
I spotted this via:
.@JohnMu FYI, your website got completely deindexed in Google. It seems Google went crazy 😱
H/T @seb_skowron & @ziptiedev pic.twitter.com/RGq6GodPsG
— Tomek Rudzki (@TomekRudzki) March 13, 2024
.@JohnMu FYI, your website got completely deindexed in Google. It seems Google went crazy 😱
H/T @seb_skowron & @ziptiedev pic.twitter.com/RGq6GodPsG
Here is how John is responding to the reaction of this information thus far:
@googlesearchc help me
— John (@JohnMu) March 13, 2024
@googlesearchc help me
How to double the traffic to your site in these 5 easy steps!
— John (@JohnMu) March 13, 2024
How to double the traffic to your site in these 5 easy steps!
I definitely do not forget to EAT, lol 🙂
— John (@JohnMu) March 13, 2024
I definitely do not forget to EAT, lol 🙂
Tell me what it finds, please!
— John (@JohnMu) March 13, 2024
Tell me what it finds, please!
It’s raining on Googlebot. What does it mean?
— John (@JohnMu) March 13, 2024
It’s raining on Googlebot. What does it mean?
You might be on to something – look what I found: pic.twitter.com/Q6Ej0A1O7Z
— John (@JohnMu) March 13, 2024
You might be on to something – look what I found: pic.twitter.com/Q6Ej0A1O7Z
Here is Fabrice Canel from the Bing team – how funny:
🙏
— John (@JohnMu) March 13, 2024
🙏
What do you all think is going on. It seems John is having fun with this one…
Be nice please.
Forum discussion at X.
Update: John posted on LinkedIn more details, he wrote:
My site’s robots.txt file was making the rounds. It’s awkward – isn’t a robots.txt file a bit like a website’s underwear? I would have put on a clean file if I had known.
But, what’s up with the file? And why is your site deindexed?
Someone suggested it might be because of the links to Google+. It’s possible. And back to the robots.txt… it’s fine – I mean, it’s how I want it, and crawlers can deal with it. Or, they should be able to, if they follow RFC9309.
The comment on top – this is of course for you, and a way of catching a hard-to-spot mistake: a double UTF BOM. Specific text file types have a special starting character. Having one is fine, you usually don’t need it. Most systems (browsers, editors) hide it. For robots.txt if you have a directive on top, and you have an accidental *second* BOM, then that will be seen as part of the directive, and the directive won’t be processed. Having a comment on top means that in the worst case, the comment will be ignored. That’s fine. You could also just have a blank line on top. Or make a clean robots.txt file. Anyway, this is a post, not a cop.
“disallow: /robots.txt” – does this make robots spin in circles? Does this deindex your site? No. My robots.txt file just has a lot of stuff in it, and it’s cleaner if it doesn’t get indexed with its content. This purely blocks the robots.txt file from being crawled for indexing purposes. I could also use the x-robots-tag HTTP header with noindex, but this way I have it in the robots.txt file too.
The length. JOHN. WHAT’S UP WITH THE SIZE OF THIS FILE? I am purposely refraining from making any jokes, do not think them in your head. This is Linkedin, we’re here for srs bzns, folks. NO JOKES. The size comes from tests of the various robots.txt testing tools that my team & I have worked on. The RFC says a crawler should parse at least 500 kibibytes (bonus likes to the first person who explains what kind of snack that is). You have to stop somewhere, you could make pages that are infinitely long (and I have, and many people have, some even on purpose). In practice what happens is that the system that checks the robots.txt file (the parser) will make a cut somewhere. I added a “disallow: /” on top of that section, so hopefully that gets picked up as a blanket disallow. It’s possible that the parser will cut off in an awkward place, like a line that has “allow: /cheeseisbest” and it stops right at the “/”, which would put the parser at an impasse (and, trivia! the allow rule will override if you have both “allow: /” and “disallow: /”). This seems very unlikely though. In practice, parsers that have to go through this will send me lightning bolts with their robot eyes. And stop crawling, if they’re polite. There are a lot of crawlers that are impolite or that put on masks when they crawl, that’s a topic for another day though.
There you have it – some robots.txt quirks – now leave my robots.txt alone 🙂
And, what’s your favorite web quirk?
John implied the site should come back quick, he wrote, “I used the Search Console tool to try something out. I might make a fast recovery if I hit the right button :-).” So the pages are in the index but they are hidden, like when you use the URL removal tool.
Update: March 14th at 1 pm ET, John’s site is back in the index: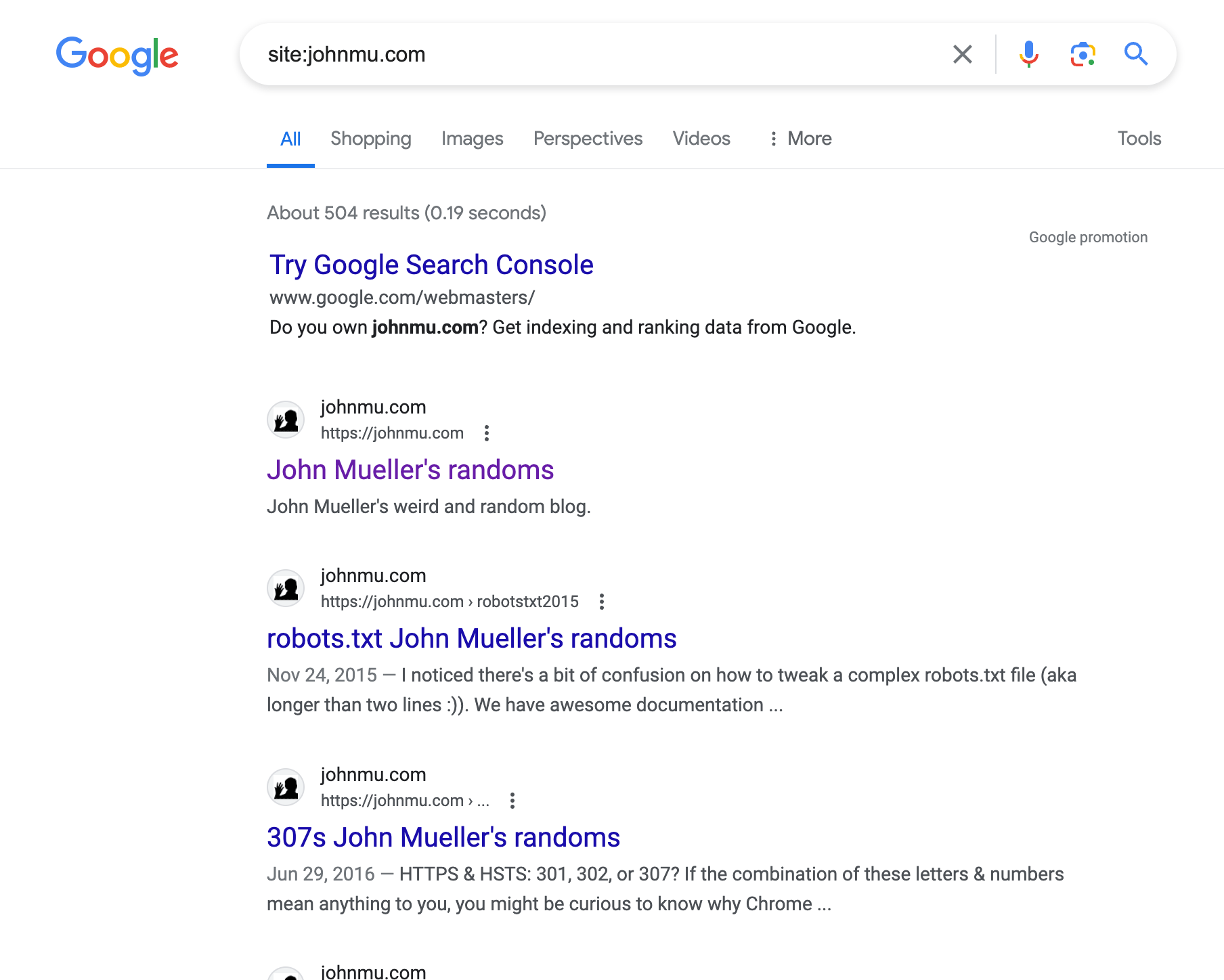
The content at the Search Engine Roundtable are the sole opinion of the authors and in no way reflect views of RustyBrick ®, Inc
Copyright © 1994-2024 RustyBrick ®, Inc. Web Development All Rights Reserved.
This work by Search Engine Roundtable is licensed under a Creative Commons Attribution 3.0 United States License. Creative Commons License and YouTube videos under YouTube’s ToS.